Fit a skew normal distribution to log-density evaluations
Source:R/skew-normal.R
fit_skew_normal.RdFit a skew normal distribution to log-density evaluations
Arguments
- x
A numeric vector of points where the density is evaluated.
- y
A numeric vector of log-density evaluations at points x.
- threshold_log_drop
A negative numeric value indicating the log-density drop threshold below which points are ignored in the fitting. Default is -6.
- temp
A numeric value for the temperature parameter k. If NA (default), it is included in the optimisation.
Value
A list with fitted parameters:
xi: location parameteromega: scale parameteralpha: shape parameterlogC: log-normalization constantk: temperature parameterrsq: R-squared of the fit
Note that logC and k are not used when fitting from a sample.
Details
This skew normal fitting function uses a weighted least squares
approach to fit the log-density evaluations provided in y at points x.
The weights are set to be the density evaluations raised to the power of
the temperature parameter k. This has somewhat an interpretation of
finding the skew normal fit that minimises the Kullback-Leibler divergence
from the true density to it.
In R-INLA, the C code implementation from which this was translated from can be found here.
Examples
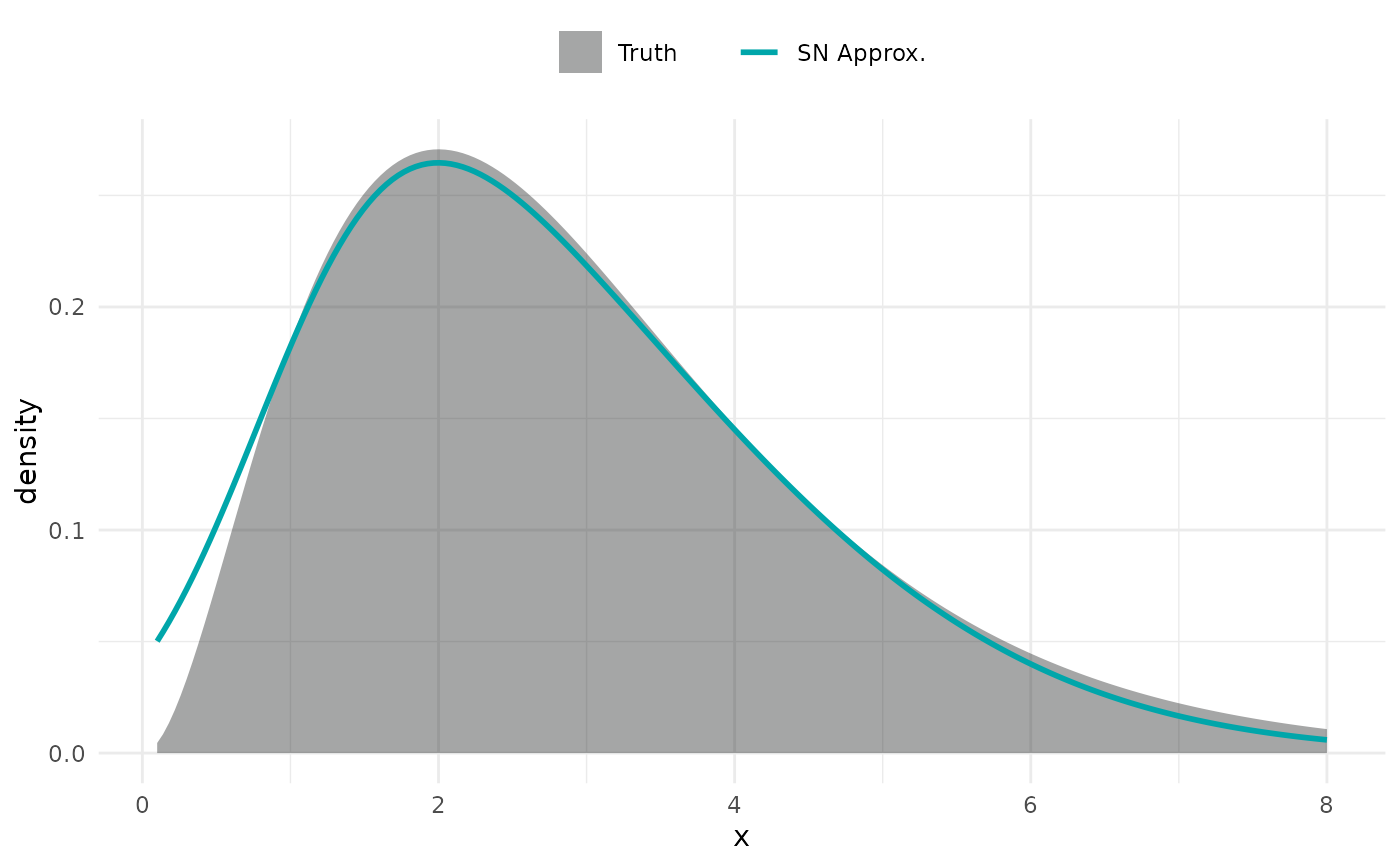
# Fit a SN curve to gamma log-density
logdens <- function(x) dgamma(x, shape = 3, rate = 1, log = TRUE)
x_grid <- seq(0.1, 8, length.out = 21)
y_log <- sapply(x_grid, logdens)
y_log <- y_log - max(y_log) # normalise to have maximum at zero
res <- fit_skew_normal(x_grid, y_log, temp = 10)
unlist(res)
#> xi omega alpha logC k rmse
#> 0.842445393 2.539226101 3.310505376 1.332422700 10.000000000 0.002109188
#> nmad
#> 0.173298470
# Compare truth vs skew-normal approximation
x_fine <- seq(0.1, 8, length.out = 200)
y_true <- exp(logdens(x_fine))
y_sn <- dsnorm(x_fine, xi = res$xi, omega = res$omega, alpha = res$alpha)
plot(x_fine, y_true, type = "n", xlab = "x", ylab = "Density", bty = "n")
polygon(c(x_fine, rev(x_fine)), c(y_true, rep(0, length(x_fine))),
col = adjustcolor("#131516", 0.25), border = NA)
lines(x_fine, y_sn, col = "#00A6AA", lwd = 2)
legend("topright", legend = c("Truth", "SN Approx."),
fill = c(adjustcolor("#131516", 0.25), NA), border = NA,
col = c(NA, "#00A6AA"), lwd = c(NA, 2), lty = c(NA, 1),
bty = "n")